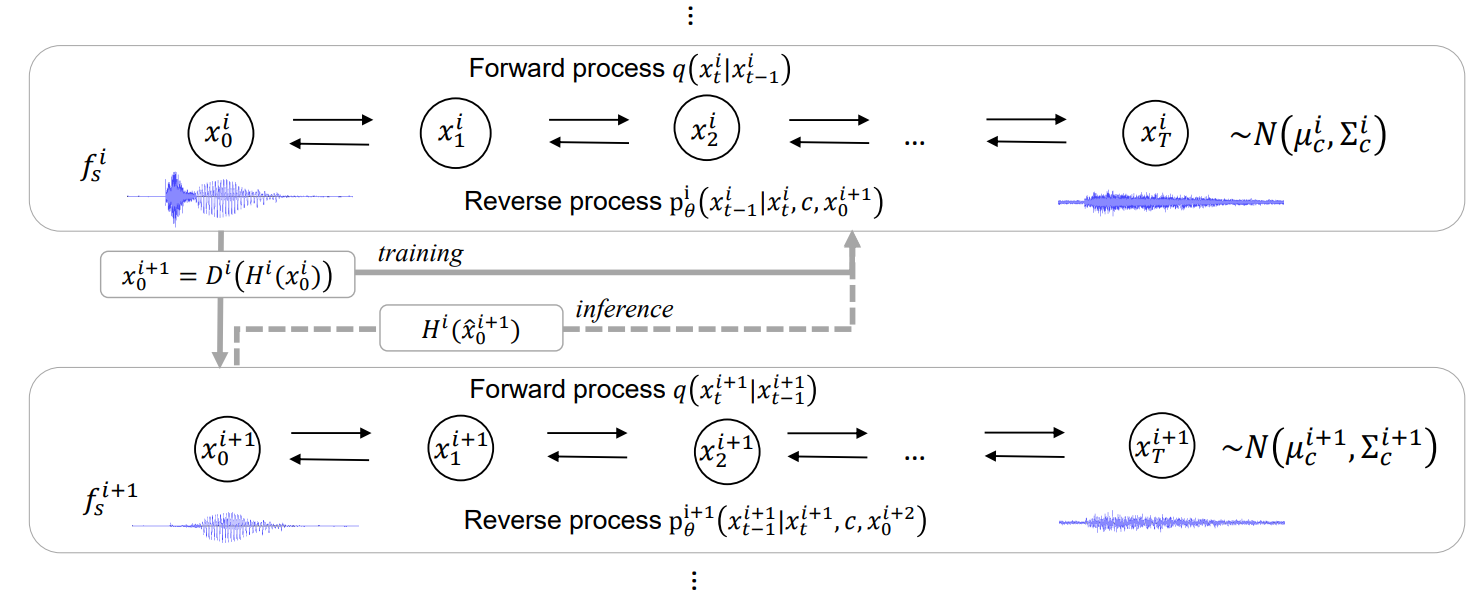
Hierarchical Diffusion Models for Singing Voice Neural Vocoder
Last Updated: 5th Mar 2023
Recent progress in deep generative models has improved the quality of neural vocoders in speech domain. However, generating a high-quality singing voice remains challenging due to a wider variety of musical expressions in pitch, loudness, and pronunciations. In this work, we propose a hierarchical diffusion model for singing voice neural vocoders. The proposed method consists of...
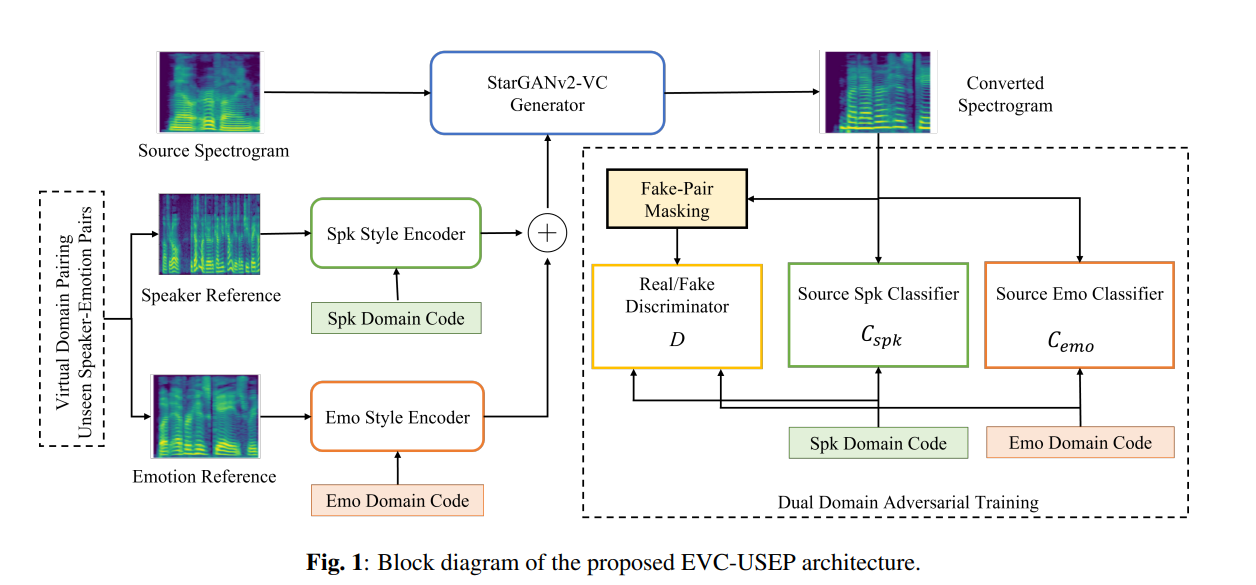
Nonparallel Emotional Voice Conversion for Unseen Speaker-Emotion Pairs Using Dual Domain Adversarial Network & Virtual Domain Pairing
Last Updated: 5th Mar 2023
Primary goal of an emotional voice conversion (EVC) system is to convert the emotion of a given speech signal from one style to another style without modifying the linguistic content of the signal. Most of the state-of-the-art approaches convert emotions for seen speaker-emotion combinations only. In this paper, we tackle the problem of converting the emotion of speakers whose only neutral data are present during the time of training and testing (i.e., unseen speaker-emotion combinations). To this end...
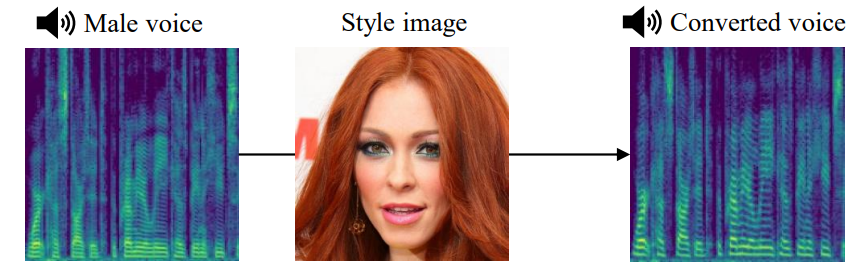
Cross-modal Face- and Voice-style Transfer
Last Updated: 5th Mar 2023
Image-to-image translation and voice conversion enable the generation of a new facial image and voice while maintaining some of the semantics such as a pose in an image and linguistic content in audio, respectively. They can aid in the content-creation process in many applications. However, as they are limited to the conversion...

Robust One-Shot Singing Voice Conversion
Last Updated: 5th Mar 2023
Many existing works on singing voice conversion (SVC) require clean recordings of target singer's voice for training. However, it is often difficult to collect them in advance and singing voices are often distorted with reverb and accompaniment music. In this work, we propose robust one-shot SVC (ROSVC) that performs any-to-any SVC robustly even on such distorted singing voices using less than 10s of a reference voice. To this end...

I am currently working as a Research Scientist in Sony Research India after my 2 year stint in Sony Japan R&D labs. I have been intrigued by machine learning since my high school and have a vision to strive to understand the complex decision process of humans and implement it with the technologies we have, to push humans one step further.
I started my journey with Hyper Spectral Images for cancer detection, pixel level segmentation and since have worked on speech source separation, text-detection and recognition, Quant algoroithms, Reinforcement Learning, Automatic Speech Recognition, Singing/Emotional Speech Voice Conversion, Vocoders and Audio Steganography. It has been a great 6 years exploring this field.