Research
Last Updated: 26th April
My research goal is to understand what intelligence means and trying to reproduce it artificially so that we can have a tool which will reduce the development process drastically in every field. I believe that to achieve this we would require a good understanding of psychology, and an intutive sense of why and how humans function.
I started my journey in the academia by focusing on Computer Vision because of its popularity and ease of applicatoin but my interests have diverged into graphs and audio as well.
I have mentioned some brief description of my publications below. To get a list of all my publications please visit here .
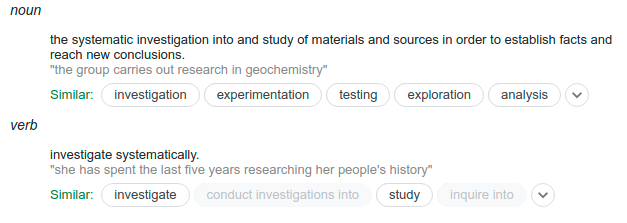
Hierarchical Diffusion Models for Singing Voice Neural Vocoder
Last Updated: 5th Mar 2023
Recent progress in deep generative models has improved the quality of neural vocoders in speech domain. However, generating a high-quality singing voice remains challenging due to a wider variety of musical expressions in pitch, loudness, and pronunciations. In this work, we propose a hierarchical diffusion model for singing voice neural vocoders. The proposed method consists of...
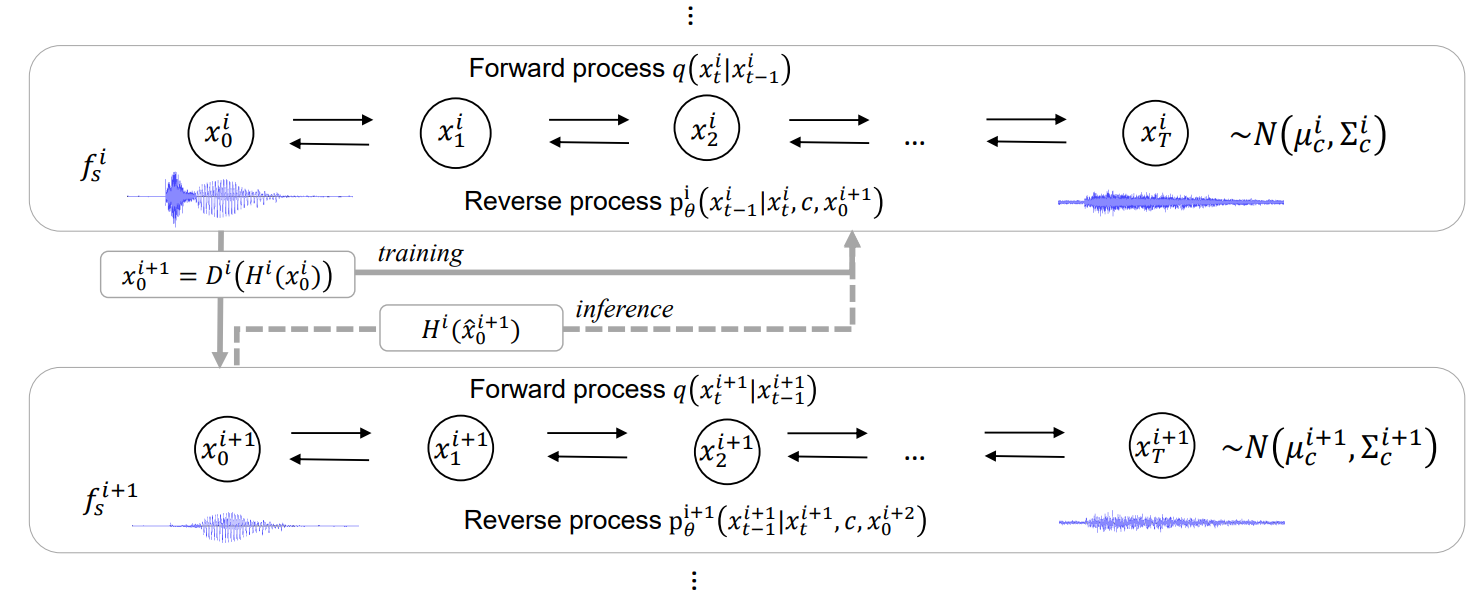
Nonparallel Emotional Voice Conversion for Unseen Speaker-Emotion Pairs Using Dual Domain Adversarial Network & Virtual Domain Pairing
Last Updated: 5th Mar 2023
Primary goal of an emotional voice conversion (EVC) system is to convert the emotion of a given speech signal from one style to another style without modifying the linguistic content of the signal. Most of the state-of-the-art approaches convert emotions for seen speaker-emotion combinations only. In this paper, we tackle the problem of converting the emotion of speakers whose only neutral data are present during the time of training and testing (i.e., unseen speaker-emotion combinations). To this end...
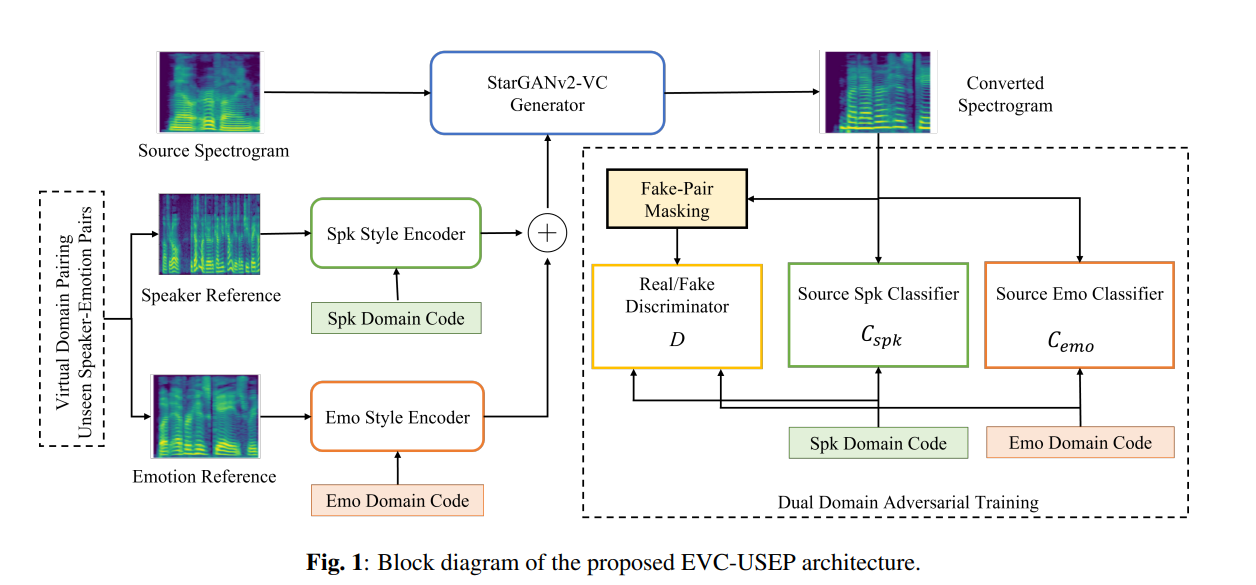
Cross-modal Face- and Voice-style Transfer
Last Updated: 5th Mar 2023
Image-to-image translation and voice conversion enable the generation of a new facial image and voice while maintaining some of the semantics such as a pose in an image and linguistic content in audio, respectively. They can aid in the content-creation process in many applications. However, as they are limited to the conversion...

Robust One-Shot Singing Voice Conversion
Last Updated: 5th Mar 2023
Many existing works on singing voice conversion (SVC) require clean recordings of target singer's voice for training. However, it is often difficult to collect them in advance and singing voices are often distorted with reverb and accompaniment music. In this work, we propose robust one-shot SVC (ROSVC) that performs any-to-any SVC robustly even on such distorted singing voices using less than 10s of a reference voice. To this end...
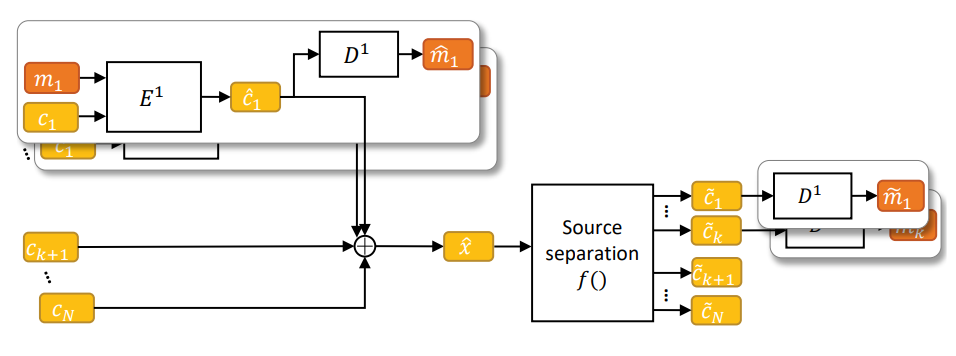
Source Mixing and Separation Robust Audio Steganography
Last Updated: 5th Mar 2023
Audio steganography aims at concealing secret information in carrier audio with imperceptible modification on the carrier. Although previous works addressed the robustness of concealed message recovery against distortions introduced during transmission, they do not address the robustness against aggressive editing such as mixing of other audio sources and source separation. In this work, we propose for the first time a steganography method that can embed information into individual sound sources in a mixture such as instrumental tracks in music. To this end...
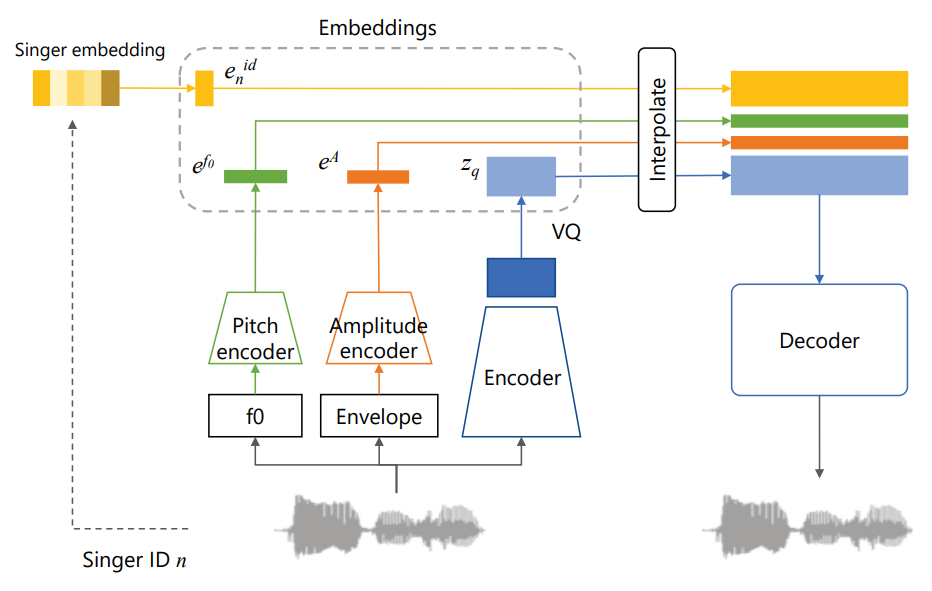
Hierarchical disentangled representation learning for singing voice conversion
Last Updated: 5th Mar 2023
Conventional singing voice conversion (SVC) methods often suffer from operating in high-resolution audio owing to a high dimensionality of data. In this paper, we propose a hierarchical representation learning that enables the learning of disentangled representations with multiple resolutions independently. With the learned disentangled representations...
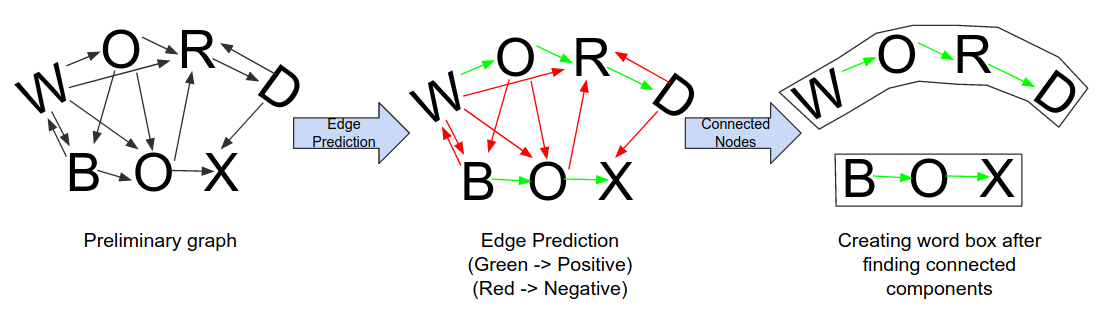
NENET: An Edge Learnable Network for Link Prediction in Scene Text
Last Updated: 27th May 2020
Text detection in scenes based on deep neural networks have shown promising results. Instead of using word bounding box regression, recent state-of-the-art methods have started focusing on character bounding box and pixel-level prediction. This necessitates the need...

Improving Voice Separation by Incorporating End-to-End Speech Recognition
Last Updated: 26th April 2020
Recent work in speech separation works good in constrained environments but still perform poorely in noisy backgrounds. To further improve voice separation in noisy environments we propose using transfer learning from Automatic Speech Recognition Models. We extract…

I am currently working as a Research Scientist in Sony Research India after my 2 year stint in Sony Japan R&D labs. I have been intrigued by machine learning since my high school and have a vision to strive to understand the complex decision process of humans and implement it with the technologies we have, to push humans one step further.
I started my journey with Hyper Spectral Images for cancer detection, pixel level segmentation and since have worked on speech source separation, text-detection and recognition, Quant algoroithms, Reinforcement Learning, Automatic Speech Recognition, Singing/Emotional Speech Voice Conversion, Vocoders and Audio Steganography. It has been a great 6 years exploring this field.